4 ways to build a simple calculator in Python - Part 2
0 CommentsIn this part of the series, I will build the calculator as a translator. The translator will evaluate the arithmetic expression according to a set of rules. It will consist of a lexer that will produce a stream of tokens from the input, and a parser that will check the tokens against a predefined set of rules - the grammar - and print out the value of the expression.
As an example, consider the grammar for simple expressions involving the digits and the
+ and - operators. The grammar is presented in the Backus Naur Form
(BNF). This is the original
notation in which grammars were described. (There are BNF variants such as EBNF (Extended
BNF) - used below - and ABNF (Augmented BNF) which make it more convenient to express
grammars).
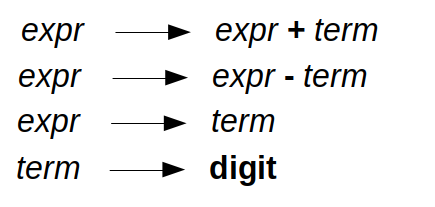
Each rule of the grammar is called a production. The symbols expr and term are called
non-terminals as, in a derivation, they can be expanded further. digit and the operator symbols, + and -, are called terminals (they "terminate" and cannot be expanded
further). The terminals are the tokens created from the input string by the lexer
(lexical analysis is discussed later).
The tokens are parsed using what is known in compiler theory as recursive descent parsing.
This simply means that a non-terminal appears on both sides of a production which is
recursively expanded to form the input string. The process can be visualized as a
parse tree as shown below. It is a parse tree for the expression 7-4+3.
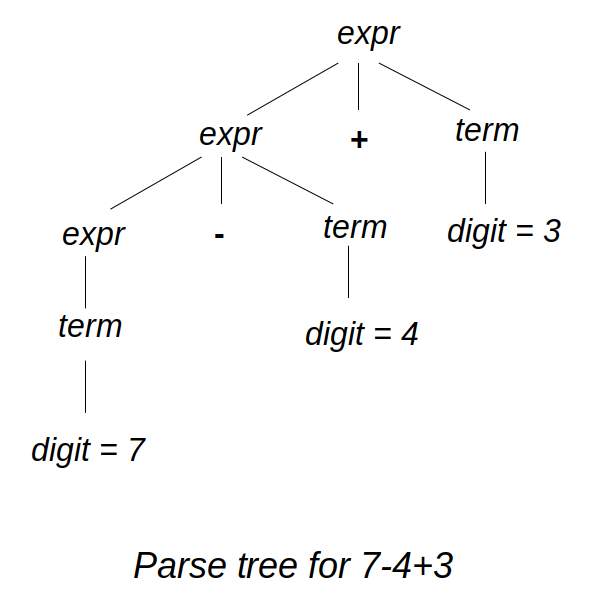
A few points to note from the figure. First, we can form the input string by
reading the leaves of the tree from left to right. Second, the non-terminal expr expands
recursively down towards the left. This is known as left-recursion. Grammars that are
left-recursive are unsuitable for top-down parsing. This is because when we write functions
mapped to the non-terminals, they become infinitely recursive. Lastly, the grammar makes
the operators left-associative. When there are additional operations like multiplication
and exponentiation, the grammar can be designed to take care of precedence of operators.
Often the BNF notation becomes unwieldy with too many productions and recursion, which is why alternative notations exist. One such notation is EBNF. I have used it below to describe the entire grammar for the translator. The grammar is concise and free of left-recursion.

The grammar is interpreted as follows. The string of characters like expr, term, etc.
are non-terminals. The terminal symbols are enclosed in double quotes. Then there are
meta-symbols like (, ), *, |, etc. The parentheses are used to group symbols. The
| is used to specify alternatives. * (Kleene star) means 0 or more repetitions. Square
brackets specify optional symbols. We can see that left-recursion has been eliminated by
using repetition (*). The only place using (right) recursion is where exponentiation is
performed. This is necessary as the order or associativity cannot be specified when using
the Kleene star *. So the factor non-terminal is repeated on the right-side to enforce
right associativity for exponentiation. There is a production for the base non-terminal that specifies the unary minus operator. The terminal num stands for each number in
the input expression.
The lexical analyzer
The following is the code for the lexical analyzer or lexer for the translator.
import re
class Num:
def __init__(self, val):
self.value = float(val) if '.' in val else int(val)
def __repr__(self):
return f'Num: {self.value}'
def lexan():
'''Lexical analyzer - creates a stream of tokens'''
inp = input('Enter the expression ')
i = 0
while i < len(inp):
c = inp[i]
if c.isdigit() or c == '.':
val = re.match(r'[.0-9]+', inp[i:])[0]
yield Num(val)
i += len(val)
else:
if inp[i:i + 2] == '**':
yield '**'
i += 1
elif c != ' ':
yield c
i += 1
lexan is a simple generator function that scans the input string for tokens - numbers
and symbols like operators and parentheses. Note that there is no error checking at this
stage - the parser (described below) will raise an exception if it encounters an invalid
token. The function loops through the characters from left to right and yields them as
tokens. Consecutive digits are grouped together with a regex and converted to a number
(either float or int) in the Num class. Then an instance of the class is yielded.
There is a separate check for the exponentiation operator ** as two characters need to
be yielded.
The parser
The parser is a set of functions that follows the grammar rules shown above. There
are functions for the grammar variables expr, term, factor and base.
The term lookahead, used as a variable in the functions below, is common in parsing
terminology. It stands for "looking ahead" one token at a time while scanning the token
stream from left to right. The match function advances the lookahead.
def expr():
'''Function to start the parsing. It performs `+` and `-` operations as
appropriate.'''
result = term()
while True:
if lookahead == '+':
match('+')
result += term()
elif lookahead == '-':
match('-')
result -= term()
else:
break
return result
def term():
'''This function performs `*` and `/` operations.'''
result = factor()
while True:
if lookahead == '*':
match('*')
result *= factor()
elif lookahead == '/':
match('/')
result /= factor()
else:
break
return result
def factor():
'''This recursive function performs the right associative power operation.'''
result = base()
if lookahead == '**':
match('**')
result **= factor()
return result
def base():
'''This function evaluates another expression in parentheses or negates a number
or simply return a number.'''
if lookahead == '(':
match('(')
result = expr()
match(')')
elif isinstance(lookahead, Num):
result = lookahead.value
match(lookahead)
elif lookahead == '-':
match('-')
result = -1 * base()
else:
match('number')
return result
def match(t):
'''Checks if token is valid and gets the next one.'''
global lookahead
if t == lookahead:
try:
lookahead = next(token_gen)
except StopIteration:
lookahead = ''
else:
raise RuntimeError(f'Malformed input. Token {lookahead}')
Following the grammar, we start the parsing with the expr function. First, we call
term, which itself calls other functions in a chain, to get a number. Then we add or
subtract another call to term in a loop to get the final result. The higher precedence
* and / operations are handled by the term function in a similar way. term calls
factor to do exponentiation. factor is a recursive function to enforce right
associativity of the operation. factor, in turn, calls base which handles numbers,
including negative numbers, and expressions in parentheses. Note that in the base
function, when the lookahead is a number, the the match is performed after the assignment
because the match function changes the lookahead.
The main function below is the driver for the translator.
def main():
'''This function sets a starting value for the `lookahead` and calls the
parser.'''
global token_gen, lookahead
token_gen = lexan()
lookahead = next(token_gen)
result = expr()
match('')
print('The expression evaluates to', result)
print()
The match function call ensures the lookahead finally is an empty string and not any
other character, like an unbalanced ), which would imply a malformed input.
Following is an example of running translator.py - the program comprising of the
functions above and whose complete listing is given below - in the terminal:
$ python3 translator.py
Enter the expression 10 + ( 3 * 2 ) ** 2 ** 3 - 25 / 5
The expression evaluates to 1679621.0
(Both the expression and its value are the same as in part 1 of this series.)
Complete listing
The complete listing of the translator program including the lexer, parser and the driver components:
import re
class Num:
def __init__(self, val):
self.value = float(val) if '.' in val else int(val)
def __repr__(self):
return f'Num: {self.value}'
def lexan():
'''Lexical analyzer - creates a stream of tokens'''
inp = input('Enter the expression ')
i = 0
while i < len(inp):
c = inp[i]
if c.isdigit() or c == '.':
val = re.match(r'[.0-9]+', inp[i:])[0]
yield Num(val)
i += len(val)
else:
if inp[i:i + 2] == '**':
yield '**'
i += 1
elif c != ' ':
yield c
i += 1
def expr():
'''Function to start the parsing. It performs `+` and `-` operations as
appropriate.'''
result = term()
while True:
if lookahead == '+':
match('+')
result += term()
elif lookahead == '-':
match('-')
result -= term()
else:
break
return result
def term():
'''This function performs `*` and `/` operations.'''
result = factor()
while True:
if lookahead == '*':
match('*')
result *= factor()
elif lookahead == '/':
match('/')
result /= factor()
else:
break
return result
def factor():
'''This recursive function performs the right associative power operation.'''
result = base()
if lookahead == '**':
match('**')
result **= factor()
return result
def base():
'''This function evaluates another expression in parentheses or negates a number
or simply return a number.'''
if lookahead == '(':
match('(')
result = expr()
match(')')
elif isinstance(lookahead, Num):
result = lookahead.value
match(lookahead)
elif lookahead == '-':
match('-')
result = -1 * base()
else:
match('number')
return result
def match(t):
'''Checks if token is valid and gets the next one.'''
global lookahead
if t == lookahead:
try:
lookahead = next(token_gen)
except StopIteration:
lookahead = ''
else:
raise RuntimeError(f'Malformed input. Token {lookahead}')
def main():
'''This function sets a starting value for the `lookahead` and calls the
parser.'''
global token_gen, lookahead
token_gen = lexan()
lookahead = next(token_gen)
result = expr()
match('')
print('The expression evaluates to', result)
print()
if __name__ == '__main__':
main()
This concludes the post. In this post, you learned about parsing, lexical analysis and the grammar for a translator. In the next post, I will show you a variation of the translator that uses an abstract syntax tree (AST) to achieve the same result.
References
-
Compilers - Principles, techniques and tools by Aho, Sethi and Ullman
-
Let's build a simple interpreter. Part 4 - Blog by Ruslan Spivak